





The two major ways of storing and accessing data across multiple servers :
- Fragmentation
- Replication
In this article, we will have a deep dive into replication.
Basic Approach :
The term Replica refers to duplication or an exact copy of data or information in this case.
In the same way, replication is the process of keeping identical copies of data on multiple servers.
Why do we use replication?
Storing data in multiple servers provides redundancy which in turn increases data availability. The main aim of replication is to make data available on multiple servers which is to make the system fault tolerant. In case of one or more servers fail, data can be retrieved from the alternate server. If there are multiple users accessing a single server there are chances of excessive load on the system which might affect the smooth functioning of the system, therefore, instead of connecting to single server, users may access data from multiple servers so that there is an equal distribution of load. That is replication provides load balancing. Replication provide Data backup and recovery by storing additional copies of data
Replica Set
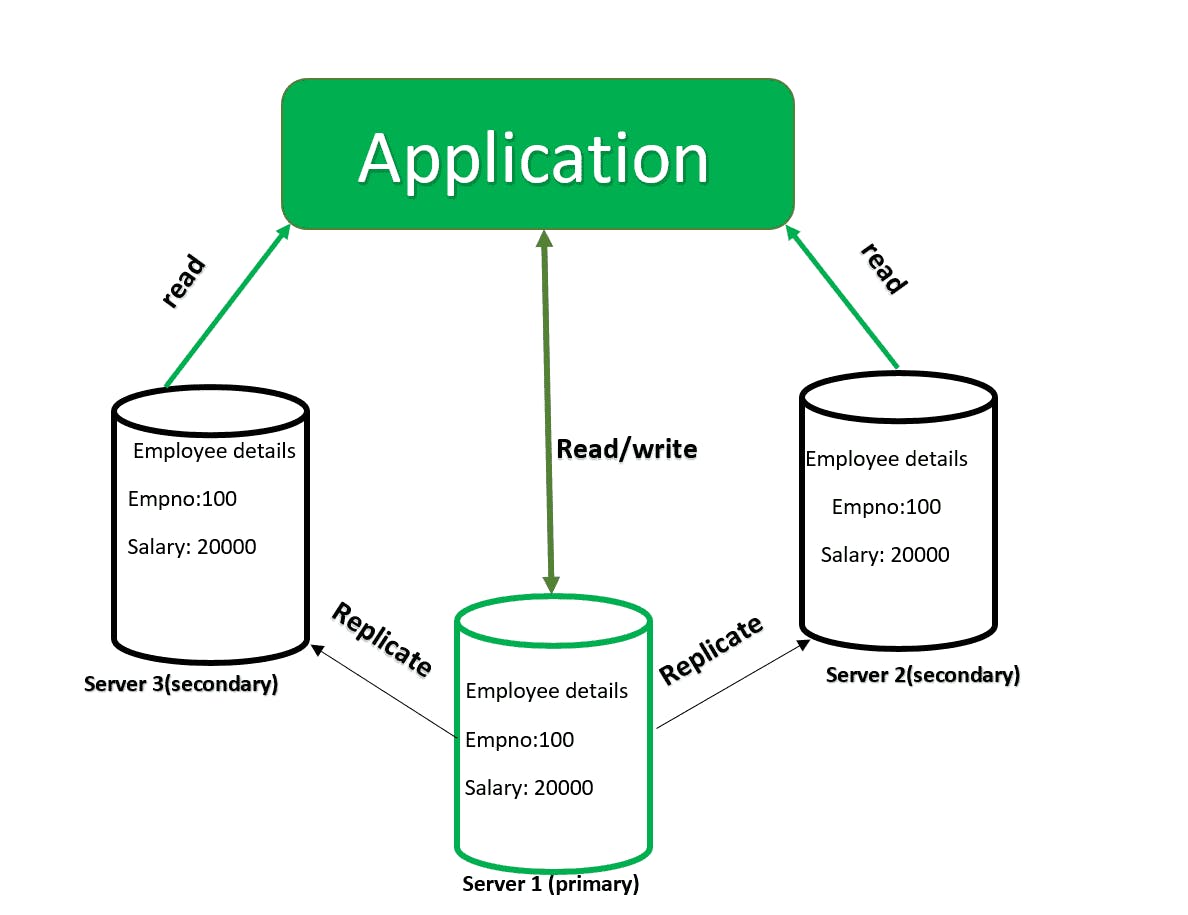
representation of replica set
A group of multiple servers is called a replica set. It contains several data-bearing nodes and optionally one arbiter node. A set must have at least three members and at most 50 members/nodes out of which one is a primary node. (You can say primary node as the main node) because it accepts all read-and-write operations from client applications.
Note: A set can contain only one primary node the rest are secondary nodes, in case of failure of the primary node one of the secondary nodes is elected as the primary node.
MEMBERS OF THE REPLICA SET:
- Primary Node
- Secondary Node
- Hidden Node
- Delayed Node
- Priority 0 Node